
Serving a user’s timeline sounds like a simple problem: read some data and return it. But as a system grows, the constraints change. How do we design a feed that supports millions of users with low latency? How do we handle celebrity users with tens of millions of followers? And what would Instagram, TikTok, or X look like if they hadn’t solved these challenges?
This post isn’t an attempt to reverse-engineer any specific platform. Instead, it’s an exploration of well-known architectural patterns used by systems that resemble modern social networks.
The Scenario: Requirements of a Modern Feed System
First, let’s understand what we’re trying to build. When designing a system, we generally think in terms of:
- Functional requirements: the core features of the system
- Non-Functional requirements: the qualities and constraints of the system (e.g. security, performance, reliability)
For a social media platform, a subset of the requirements might look like this:
- Functional requirements:
- users should be able to create posts
- users should be able to see a timeline of posts from users that they follow
- Non-Functional requirements:
- the system should scale to hundreds of millions of daily active users
- the system should have low latency
We’re going to focus on designing the second functional requirement (serving a user’s feed) while respecting the non-functional ones.
Naive Approach: Fanout-on-Read
The simplest solution is to build a user’s feed (timeline of posts from users that they follow) at the moment they request it:
- retrieve the list of users they follow
- fetch posts from each of those users
- merge and sort the posts in reverse chronological order
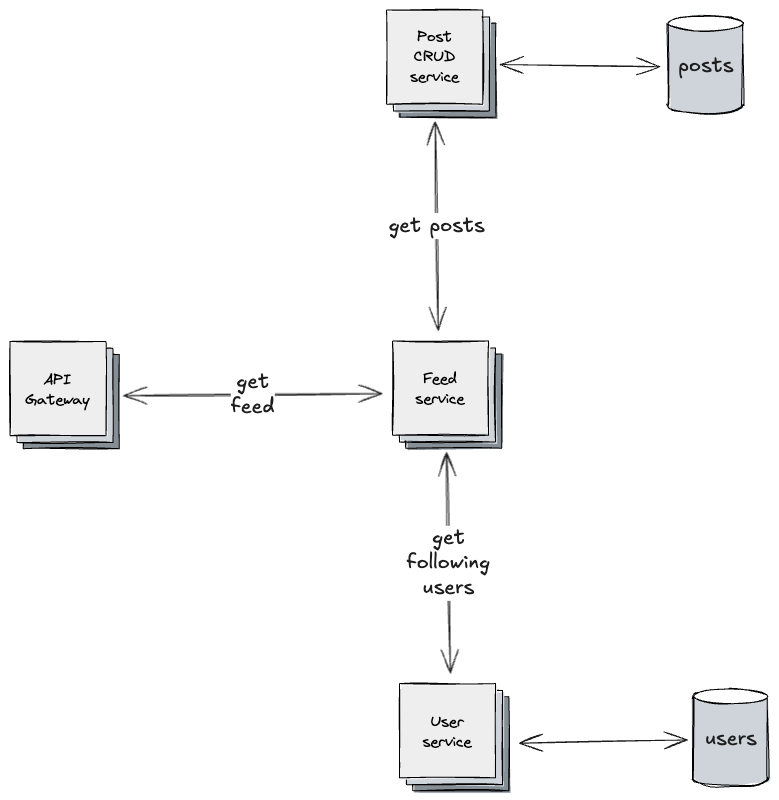
Fanout-on-Read: the feed service fetches posts from followed users on demand, merging them at request time.
This pattern is known as Fanout-on-Read. The key idea is that the system assembles data dynamically every time the user loads their feed.
This approach meets the functional requirement in a clear and easy-to-reason-about way. Writes are fast because they involve only a single operation, there’s no data duplication, and the system scales to a reasonably large user base.
However, it comes with inherent disadvantages that conflict with our non-functional requirements, especially low latency. Reads require multiple queries, and response times increase as the number of followed users grows. Also, celebrity users, who are followed by millions, cause huge data scans.
So, if we want to satisfy the low-latency requirement, we need to come up with a more sophisticated solution.
Scalable Approach: Fanout-on-Write
Instead of constructing a user’s feed when requested, we can work proactively, pre-calculating feeds when users create posts. Then, read becomes trivial, as it consists of simply fetching a prepared feed. This follows the Fanout-on-Write pattern and it works as follows:
- when a user creates a post, a message is published to a queue
- a service consumes the message
- it fetches the author’s followers
- it updates the followers’ feeds and stores them in a feed cache
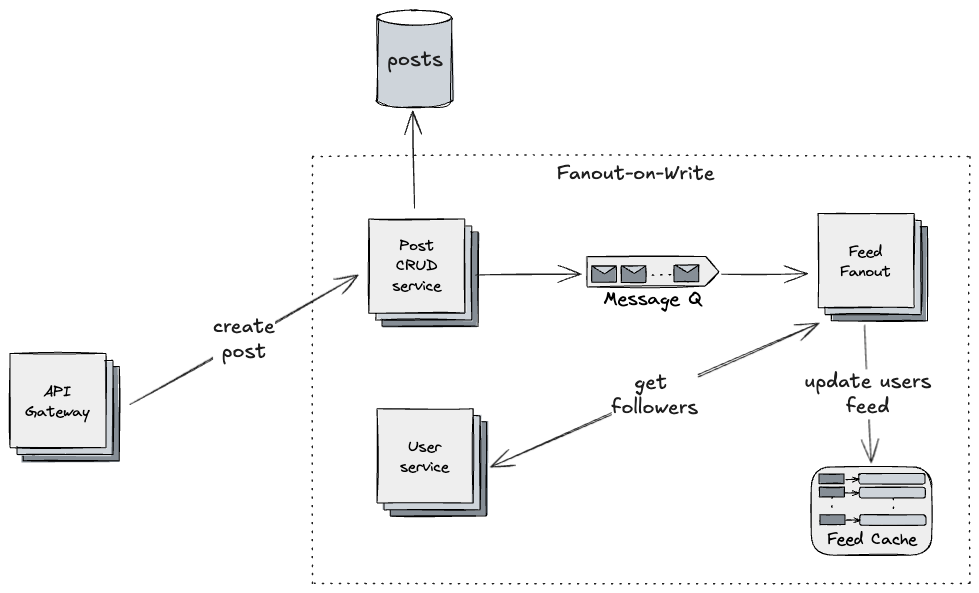
Fanout-on-Write: posts trigger asynchronous fanout through a message queue, updating follower feeds proactively.
When users request their feed, the system simply fetches it from the cache.

Reading a precomputed feed: the Feed service retrieves a user’s feed directly from the Feed Cache for low-latency reads.
This makes reads extremely fast and latency predictable. The number of people a user follows no longer determines how expensive a read is. Repeated refreshes don’t trigger recalculations.
The trade-off is slower writes. A single write could result in thousands or even millions or feeds getting proactively updated. Also, storage increases, as multiple copies of the same post are stored in many different cached feeds. Lastly, the system becomes eventually consistent. It is perfectly possible that a user might get a feed which doesn’t include a post created moments ago, as the Fanout-on-Write process works asynchronously. However, for a social media platform, this trade-off is often acceptable (we couldn’t apply a similar solution to a stock trading system).
Overall, this design prioritizes read speed, satisfying the low-latency requirement. But it introduces a new challenge: celebrity users.
Special Case: Celebrity/High-Fanout Users
A single post from a user with 100 million followers could trigger 100 million fanout writes. This can overwhelm the system and dramatically increase write latency.
A hybrid approach works well for these cases. By using a configurable threshold to distinguish “normal” from “celebrity” users, we can:
- use Fanout-on-Write for normal users
- use Fanout-on-Read for celebrity users
When a celebrity user creates a post, this doesn’t trigger the Fanout-on-Write flow. Then, when a user requests their feed, the system:
- fetches the precomputed feed from the cache
- fetches posts from celebrity users using Fanout-on-Read approach
- merges and sorts the posts
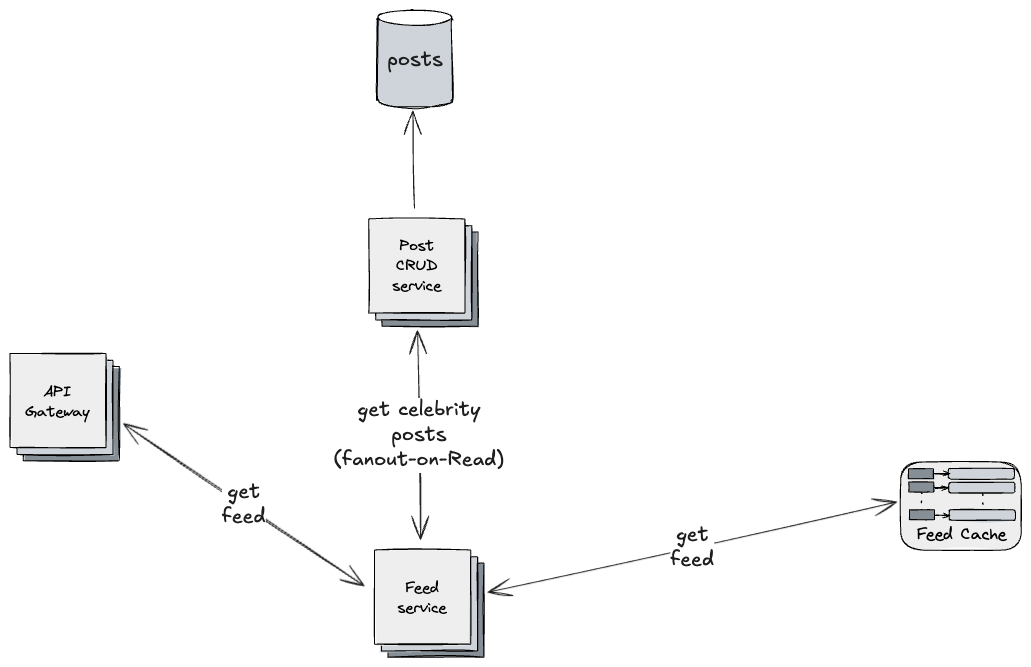
Hybrid fanout strategy: posts from normal users are received from Fanout-on-Write updates, while celebrity posts are fetched via Fanout-on-Read to avoid high fanout spikes
This avoids enormous fanouts when celebrity users create posts, while still giving fast reads for the majority of users. It also reduces spike risks and avoids saturating queues. Further optimizations, such as caching celebrity posts, can make this even more efficient.
This strategy relies on the assumption that high-fanout posts are rare compared to posts from typical users, which tends to hold true.
Beyond Social Media: Where Else Is This Used?
Fanout-on-Write is a powerful pattern used far beyond social feeds. Examples include:
- E-commerce: distributing product updates to denormalized catalogs
- Notifications systems: pushing notifications to millions of subscribers
- Content recommendation systems: powering “For you” feeds on news, video, or shopping platforms
- Learning platforms: updating dashboards for instructors, admins, and students
- Gaming leaderboards: pushing updated stats into multiple leaderboard shards
All of these involve precomputing and pushing data into ready-to-read stores.
Conclusion
Solving the same problem under different non-functional requirements can lead to fundamentally different architectures. Constructing a feed is trivial when scale is small or latency is unimportant. But when millions of users and sub-second response times enter the picture, the problem changes entirely.
Simple solutions aren’t bad, so long as they meet the requirements. Starting small and evolving the architecture as scale grows is often the most pragmatic approach. Over-engineering to satisfy hypothetical future needs usually isn’t.
Good architecture is ultimately about trade-offs, not silver bullets.